The evaluation of Qwen2 Language Model Family primarily emphasizes their performance in natural language understanding, general question answering, coding, mathematics, scientific knowledge, reasoning, and multilingual capabilities.
The Qwen2 Language Model evaluation encompasses a diverse set of datasets across various tasks:
English tasks include MMLU (5-shot), MMLU-Pro (5-shot), GPQA (5-shot), Theorem QA (5-shot), BBH (3-shot), HellaSwag (10-shot), Winogrande (5-shot), TruthfulQA (0-shot), and ARC-C (25-shot).
For coding, EvalPlus (0-shot) covers HumanEval, MBPP, HumanEval+, and MBPP+, while MultiPL-E (0-shot) evaluates models on languages such as Python, C++, JAVA, PHP, TypeScript, C#, Bash, and JavaScript.
Math tasks are assessed using GSM8K (4-shot) and MATH (4-shot). Chinese tasks include C-Eval (5-shot) and CMMLU (5-shot).
For multilingual tasks, the evaluation includes Multi-Exam (M3Exam 5-shot, IndoMMLU 3-shot, ruMMLU 5-shot, mMMLU 5-shot), Multi-Understanding (BELEBELE 5-shot, XCOPA 5-shot, XWinograd 5-shot, XStoryCloze 0-shot, PAWS-X 5-shot), Multi-Mathematics (MGSM 8-shot), and Multi-Translation (Flores-101 5-shot).
Qwen2-72B performance
| Datasets | DeepSeek-V2 | Mixtral-8x22B | Llama-3-70B | Qwen1.5-72B | Qwen1.5-110B | Qwen2-72B |
|---|---|---|---|---|---|---|
| Architecture | MoE | MoE | Dense | Dense | Dense | Dense |
| #Activated Params | 21B | 39B | 70B | 72B | 110B | 72B |
| #Params | 236B | 140B | 70B | 72B | 110B | 72B |
| English | ||||||
| MMLU | 78.5 | 77.8 | 79.5 | 77.5 | 80.4 | 84.2 |
| MMLU-Pro | - | 49.5 | 52.8 | 45.8 | 49.4 | 55.6 |
| GPQA | - | 34.3 | 36.3 | 36.3 | 35.9 | 37.9 |
| Theorem QA | - | 35.9 | 32.3 | 29.3 | 34.9 | 43.1 |
| BBH | 78.9 | 78.9 | 81.0 | 65.5 | 74.8 | 82.4 |
| HellaSwag | 87.8 | 88.7 | 88.0 | 86.0 | 87.5 | 87.6 |
| WindoGrande | 84.8 | 85.0 | 85.3 | 83.0 | 83.5 | 85.1 |
| ARC-C | 70.0 | 70.7 | 68.8 | 65.9 | 69.6 | 68.9 |
| TruthfulQA | 42.2 | 51.0 | 45.6 | 59.6 | 49.6 | 54.8 |
| Coding | ||||||
| HumanEval | 45.7 | 46.3 | 48.2 | 46.3 | 54.3 | 64.6 |
| MBPP | 73.9 | 71.7 | 70.4 | 66.9 | 70.9 | 76.9 |
| EvalPlus | 55.0 | 54.1 | 54.8 | 52.9 | 57.7 | 65.4 |
| MultiPL-E | 44.4 | 46.7 | 46.3 | 41.8 | 52.7 | 59.6 |
| Mathematics | ||||||
| GSM8K | 79.2 | 83.7 | 83.0 | 79.5 | 85.4 | 89.5 |
| MATH | 43.6 | 41.7 | 42.5 | 34.1 | 49.6 | 51.1 |
| Chinese | ||||||
| C-Eval | 81.7 | 54.6 | 65.2 | 84.1 | 89.1 | 91.0 |
| CMMLU | 84.0 | 53.4 | 67.2 | 83.5 | 88.3 | 90.1 |
| Multilingual | ||||||
| Mulit-Exam | 67.5 | 63.5 | 70.0 | 66.4 | 75.6 | 76.6 |
| Multi-Understanding | 77.0 | 77.7 | 79.9 | 78.2 | 78.2 | 80.7 |
| Multi-Mathematics | 58.8 | 62.9 | 67.1 | 61.7 | 64.4 | 76.0 |
| Multi-Translation | 36.0 | 23.3 | 38.0 | 35.6 | 36.2 | 37.8 |
Qwen2-57B-A14B
| Datasets | Jamba | Mixtral-8x7B | Yi-1.5-34B | Qwen1.5-32B | Qwen2-57B-A14B |
|---|---|---|---|---|---|
| Architecture | MoE | MoE | Dense | Dense | MoE |
| #Activated Params | 12B | 12B | 34B | 32B | 14B |
| #Params | 52B | 47B | 34B | 32B | 57B |
| English | |||||
| MMLU | 67.4 | 71.8 | 77.1 | 74.3 | 76.5 |
| MMLU-Pro | - | 41.0 | 48.3 | 44.0 | 43.0 |
| GPQA | - | 29.2 | - | 30.8 | 34.3 |
| Theorem QA | - | 23.2 | - | 28.8 | 33.5 |
| BBH | 45.4 | 50.3 | 76.4 | 66.8 | 67.0 |
| HellaSwag | 87.1 | 86.5 | 85.9 | 85.0 | 85.2 |
| Winogrande | 82.5 | 81.9 | 84.9 | 81.5 | 79.5 |
| ARC-C | 64.4 | 66.0 | 65.6 | 63.6 | 64.1 |
| TruthfulQA | 46.4 | 51.1 | 53.9 | 57.4 | 57.7 |
| Coding | |||||
| HumanEval | 29.3 | 37.2 | 46.3 | 43.3 | 53.0 |
| MBPP | - | 63.9 | 65.5 | 64.2 | 71.9 |
| EvalPlus | - | 46.4 | 51.9 | 50.4 | 57.2 |
| MultiPL-E | - | 39.0 | 39.5 | 38.5 | 49.8 |
| Mathematics | |||||
| GSM8K | 59.9 | 62.5 | 82.7 | 76.8 | 80.7 |
| MATH | - | 30.8 | 41.7 | 36.1 | 43.0 |
| Chinese | |||||
| C-Eval | - | - | - | 83.5 | 87.7 |
| CMMLU | - | - | 84.8 | 82.3 | 88.5 |
| Multilingual | |||||
| Multi-Exam | - | 56.1 | 58.3 | 61.6 | 65.5 |
| Multi-Understanding | - | 70.7 | 73.9 | 76.5 | 77.0 |
| Multi-Mathematics | - | 45.0 | 49.3 | 56.1 | 62.3 |
| Multi-Translation | - | 29.8 | 30.0 | 33.5 | 34.5 |
Qwen2-7B
| Datasets | Mistral-7B | Gemma-7B | Llama-3-8B | Qwen1.5-7B | Qwen2-7B |
|---|---|---|---|---|---|
| # Params | 7.2B | 8.5B | 8.0B | 7.7B | 7.6B |
| # Non-emb Params | 7.0B | 7.8B | 7.0B | 6.5B | 6.5B |
| English | |||||
| MMLU | 64.2 | 64.6 | 66.6 | 61.0 | 70.3 |
| MMLU-Pro | 30.9 | 33.7 | 35.4 | 29.9 | 40.0 |
| GPQA | 24.7 | 25.7 | 25.8 | 26.7 | 31.8 |
| Theorem QA | 19.2 | 21.5 | 22.1 | 14.2 | 31.1 |
| BBH | 56.1 | 55.1 | 57.7 | 40.2 | 62.6 |
| HellaSwag | 83.2 | 82.2 | 82.1 | 78.5 | 80.7 |
| Winogrande | 78.4 | 79.0 | 77.4 | 71.3 | 77.0 |
| ARC-C | 60.0 | 61.1 | 59.3 | 54.2 | 60.6 |
| TruthfulQA | 42.2 | 44.8 | 44.0 | 51.1 | 54.2 |
| Coding | |||||
| HumanEval | 29.3 | 37.2 | 33.5 | 36.0 | 51.2 |
| MBPP | 51.1 | 50.6 | 53.9 | 51.6 | 65.9 |
| EvalPlus | 36.4 | 39.6 | 40.3 | 40.0 | 54.2 |
| MultiPL-E | 29.4 | 29.7 | 22.6 | 28.1 | 46.3 |
| Mathematics | |||||
| GSM8K | 52.2 | 46.4 | 56.0 | 62.5 | 79.9 |
| MATH | 13.1 | 24.3 | 20.5 | 20.3 | 44.2 |
| Chinese | |||||
| C-Eval | 47.4 | 43.6 | 49.5 | 74.1 | 83.2 |
| CMMLU | - | - | 50.8 | 73.1 | 83.9 |
| Multilingual | |||||
| Multi-Exam | 47.1 | 42.7 | 52.3 | 47.7 | 59.2 |
| Multi-Understanding | 63.3 | 58.3 | 68.6 | 67.6 | 72.0 |
| Multi-Mathematics | 26.3 | 39.1 | 36.3 | 37.3 | 57.5 |
| Multi-Translation | 23.3 | 31.2 | 31.9 | 28.4 | 31.5 |
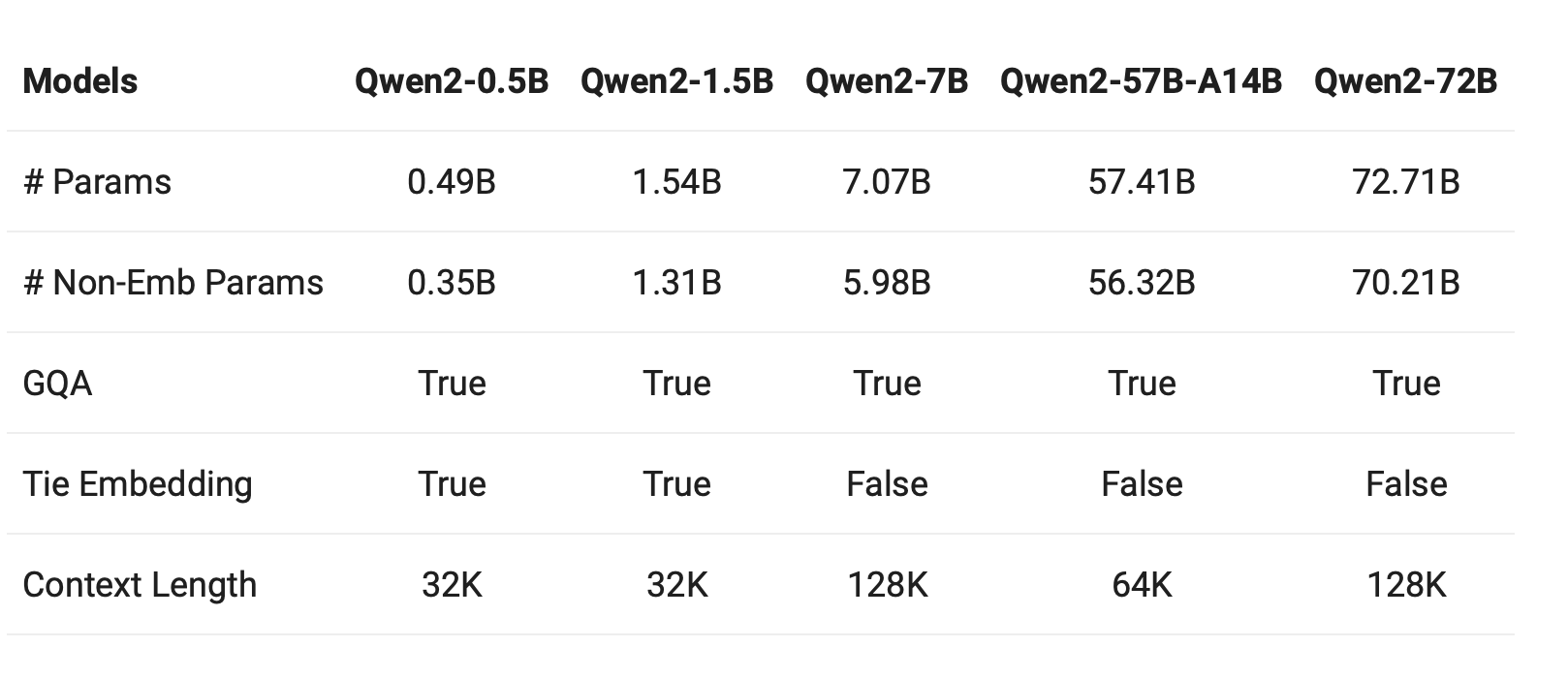
Qwen2-0.5B & Qwen2-1.5B
| Datasets | Phi-2 | Gemma-2B | MiniCPM | Qwen1.5-1.8B | Qwen2-0.5B | Qwen2-1.5B |
|---|---|---|---|---|---|---|
| #Non-Emb Params | 2.5B | 2.0B | 2.4B | 1.3B | 0.35B | 1.3B |
| MMLU | 52.7 | 42.3 | 53.5 | 46.8 | 45.4 | 56.5 |
| MMLU-Pro | - | 15.9 | - | - | 14.7 | 21.8 |
| Theorem QA | - | - | - | - | 8.9 | 15.0 |
| HumanEval | 47.6 | 22.0 | 50.0 | 20.1 | 22.0 | 31.1 |
| MBPP | 55.0 | 29.2 | 47.3 | 18.0 | 22.0 | 37.4 |
| GSM8K | 57.2 | 17.7 | 53.8 | 38.4 | 36.5 | 58.5 |
| MATH | 3.5 | 11.8 | 10.2 | 10.1 | 10.7 | 21.7 |
| BBH | 43.4 | 35.2 | 36.9 | 24.2 | 28.4 | 37.2 |
| HellaSwag | 73.1 | 71.4 | 68.3 | 61.4 | 49.3 | 66.6 |
| Winogrande | 74.4 | 66.8 | - | 60.3 | 56.8 | 66.2 |
| ARC-C | 61.1 | 48.5 | - | 37.9 | 31.5 | 43.9 |
| TruthfulQA | 44.5 | 33.1 | - | 39.4 | 39.7 | 45.9 |
| C-Eval | 23.4 | 28.0 | 51.1 | 59.7 | 58.2 | 70.6 |
| CMMLU | 24.2 | - | 51.1 | 57.8 | 55.1 | 70.3 |
Instruction-tuned Model Evaluation
Qwen2-72B-Instruct
| Datasets | Llama-3-70B-Instruct | Qwen1.5-72B-Chat | Qwen2-72B-Instruct |
|---|---|---|---|
| English | |||
| MMLU | 82.0 | 75.6 | 82.3 |
| MMLU-Pro | 56.2 | 51.7 | 64.4 |
| GPQA | 41.9 | 39.4 | 42.4 |
| TheroemQA | 42.5 | 28.8 | 44.4 |
| MT-Bench | 8.95 | 8.61 | 9.12 |
| Arena-Hard | 41.1 | 36.1 | 48.1 |
| IFEval (Prompt Strict-Acc.) | 77.3 | 55.8 | 77.6 |
| Coding | |||
| HumanEval | 81.7 | 71.3 | 86.0 |
| MBPP | 82.3 | 71.9 | 80.2 |
| MultiPL-E | 63.4 | 48.1 | 69.2 |
| EvalPlus | 75.2 | 66.9 | 79.0 |
| LiveCodeBench | 29.3 | 17.9 | 35.7 |
| Mathematics | |||
| GSM8K | 93.0 | 82.7 | 91.1 |
| MATH | 50.4 | 42.5 | 59.7 |
| Chinese | |||
| C-Eval | 61.6 | 76.1 | 83.8 |
| AlignBench | 7.42 | 7.28 | 8.27 |
Qwen2-57B-A14B-Instruct
| Datasets | Mixtral-8x7B-Instruct-v0.1 | Yi-1.5-34B-Chat | Qwen1.5-32B-Chat | Qwen2-57B-A14B-Instruct |
|---|---|---|---|---|
| Architecture | MoE | Dense | Dense | MoE |
| #Activated Params | 12B | 34B | 32B | 14B |
| #Params | 47B | 34B | 32B | 57B |
| English | ||||
| MMLU | 71.4 | 76.8 | 74.8 | 75.4 |
| MMLU-Pro | 43.3 | 52.3 | 46.4 | 52.8 |
| GPQA | - | - | 30.8 | 34.3 |
| TheroemQA | - | - | 30.9 | 33.1 |
| MT-Bench | 8.30 | 8.50 | 8.30 | 8.55 |
| Coding | ||||
| HumanEval | 45.1 | 75.2 | 68.3 | 79.9 |
| MBPP | 59.5 | 74.6 | 67.9 | 70.9 |
| MultiPL-E | - | - | 50.7 | 66.4 |
| EvalPlus | 48.5 | - | 63.6 | 71.6 |
| LiveCodeBench | 12.3 | - | 15.2 | 25.5 |
| Mathematics | ||||
| GSM8K | 65.7 | 90.2 | 83.6 | 79.6 |
| MATH | 30.7 | 50.1 | 42.4 | 49.1 |
| Chinese | ||||
| C-Eval | - | - | 76.7 | 80.5 |
| AlignBench | 5.70 | 7.20 | 7.19 | 7.36 |
Qwen2-7B-Instruct
| Datasets | Llama-3-8B-Instruct | Yi-1.5-9B-Chat | GLM-4-9B-Chat | Qwen1.5-7B-Chat | Qwen2-7B-Instruct |
|---|---|---|---|---|---|
| English | |||||
| MMLU | 68.4 | 69.5 | 72.4 | 59.5 | 70.5 |
| MMLU-Pro | 41.0 | - | - | 29.1 | 44.1 |
| GPQA | 34.2 | - | - | 27.8 | 25.3 |
| TheroemQA | 23.0 | - | - | 14.1 | 25.3 |
| MT-Bench | 8.05 | 8.20 | 8.35 | 7.60 | 8.41 |
| Coding | |||||
| Humaneval | 62.2 | 66.5 | 71.8 | 46.3 | 79.9 |
| MBPP | 67.9 | - | - | 48.9 | 67.2 |
| MultiPL-E | 48.5 | - | - | 27.2 | 59.1 |
| Evalplus | 60.9 | - | - | 44.8 | 70.3 |
| LiveCodeBench | 17.3 | - | - | 6.0 | 26.6 |
| Mathematics | |||||
| GSM8K | 79.6 | 84.8 | 79.6 | 60.3 | 82.3 |
| MATH | 30.0 | 47.7 | 50.6 | 23.2 | 49.6 |
| Chinese | |||||
| C-Eval | 45.9 | - | 75.6 | 67.3 | 77.2 |
| AlignBench | 6.20 | 6.90 | 7.01 | 6.20 | 7.21 |
Qwen2-0.5B-Instruct & Qwen2-1.5B-Instruct
| Datasets | Qwen1.5-0.5B-Chat | Qwen2-0.5B-Instruct | Qwen1.5-1.8B-Chat | Qwen2-1.5B-Instruct |
|---|---|---|---|---|
| MMLU | 35.0 | 37.9 | 43.7 | 52.4 |
| HumanEval | 9.1 | 17.1 | 25.0 | 37.8 |
| GSM8K | 11.3 | 40.1 | 35.3 | 61.6 |
| C-Eval | 37.2 | 45.2 | 55.3 | 63.8 |
| IFEval (Prompt Strict-Acc.) | 14.6 | 20.0 | 16.8 | 29.0 |
Multilingual Capability of Instruction-Tuned Models
Qwen Dev Team assessed Qwen2 instruction-tuned models against other recent large language models (LLMs) using several cross-lingual open benchmarks and human evaluations. For benchmarking, they focused on two evaluation datasets:
- M-MMLU from Okapi: A multilingual commonsense evaluation, tested on a subset of languages including Arabic (ar), German (de), Spanish (es), French (fr), Italian (it), Dutch (nl), Russian (ru), Ukrainian (uk), Vietnamese (vi), and Chinese (zh).
- MGSM: A math evaluation across languages such as German (de), English (en), Spanish (es), French (fr), Japanese (ja), Russian (ru), Thai (th), Chinese (zh), and Bengali (bn).
The results were averaged over languages for each benchmark and are presented as follows:
| Models | M-MMLU (5-shot) | MGSM (0-shot, CoT) |
|---|---|---|
| Proprietary LLMs | ||
| GPT-4-0613 | 78.0 | 87.0 |
| GPT-4-Turbo-0409 | 79.3 | 90.5 |
| GPT-4o-0513 | 83.2 | 89.6 |
| Claude-3-Opus-20240229 | 80.1 | 91.0 |
| Claude-3-Sonnet-20240229 | 71.0 | 85.6 |
| Open-source LLMs | ||
| command-r-plus-110b | 65.5 | 63.5 |
| Qwen1.5-7B-Chat | 50.0 | 37.0 |
| Qwen1.5-32B-Chat | 65.0 | 65.0 |
| Qwen1.5-72B-Chat | 68.4 | 71.7 |
| Qwen2-7B-Instruct | 60.0 | 57.0 |
| Qwen2-57B-A14B-Instruct | 68.0 | 74.0 |
| Qwen2-72B-Instruct | 78.0 | 86.6 |
For human evaluation, they compare Qwen2-72B-Instruct with GPT3.5, GPT4 and Claude-3-Opus using in-house evaluation set, which includes 10 languages ar, es, fr, ko, th, vi, pt, id, ja and ru (the scores range from 1~5):
| Models | ar | es | fr | ko | th | vi | pt | id | ja | ru | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Claude-3-Opus-20240229 | 4.15 | 4.31 | 4.23 | 4.23 | 4.01 | 3.98 | 4.09 | 4.40 | 3.85 | 4.25 | 4.15 |
| GPT-4o-0513 | 3.55 | 4.26 | 4.16 | 4.40 | 4.09 | 4.14 | 3.89 | 4.39 | 3.72 | 4.32 | 4.09 |
| GPT-4-Turbo-0409 | 3.44 | 4.08 | 4.19 | 4.24 | 4.11 | 3.84 | 3.86 | 4.09 | 3.68 | 4.27 | 3.98 |
| Qwen2-72B-Instruct | 3.86 | 4.10 | 4.01 | 4.14 | 3.75 | 3.91 | 3.97 | 3.83 | 3.63 | 4.15 | 3.93 |
| GPT-4-0613 | 3.55 | 3.92 | 3.94 | 3.87 | 3.83 | 3.95 | 3.55 | 3.77 | 3.06 | 3.63 | 3.71 |
| GPT-3.5-Turbo-1106 | 2.52 | 4.07 | 3.47 | 2.37 | 3.38 | 2.90 | 3.37 | 3.56 | 2.75 | 3.24 | 3.16 |
Grouped by task types, the results are shown as follows:
| Models | Knowledge | Understanding | Creation | Math |
|---|---|---|---|---|
| Claude-3-Opus-20240229 | 3.64 | 4.45 | 4.42 | 3.81 |
| GPT-4o-0513 | 3.76 | 4.35 | 4.45 | 3.53 |
| GPT-4-Turbo-0409 | 3.42 | 4.29 | 4.35 | 3.58 |
| Qwen2-72B-Instruct | 3.41 | 4.07 | 4.36 | 3.61 |
| GPT-4-0613 | 3.42 | 4.09 | 4.10 | 3.32 |
| GPT-3.5-Turbo-1106 | 3.37 | 3.67 | 3.89 | 2.97 |
These results demonstrate the strong multilingual capabilities of Qwen2 instruction-tuned models.
Check out Qwen2 Family Models:
Read our Blog: