Qwen2
Qwen2 is an advanced suite of foundational and instruction-tuned language models, with parameters ranging from 0.5 to 72 billion. It includes both dense models and a Mixture-of-Experts model.
Qwen2 outperforms most previous open-weight models, including its predecessor Qwen1.5, and demonstrates competitive performance against proprietary models across various benchmarks, including language understanding, generation, multilingual capabilities, coding, mathematics, and reasoning.
Qwen Version 2 showcases strong multilingual abilities, excelling in around 30 languages, including English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, highlighting its versatility and global reach.
We are an independent community dedicated to exploring and understanding the Qwen2 models.
Qwen2 Model Suite
The Qwen2 Model Suite offers a comprehensive range of advanced language and multimodal models, spanning from foundational to instruction-tuned variants, designed for versatile applications and high-performance tasks.
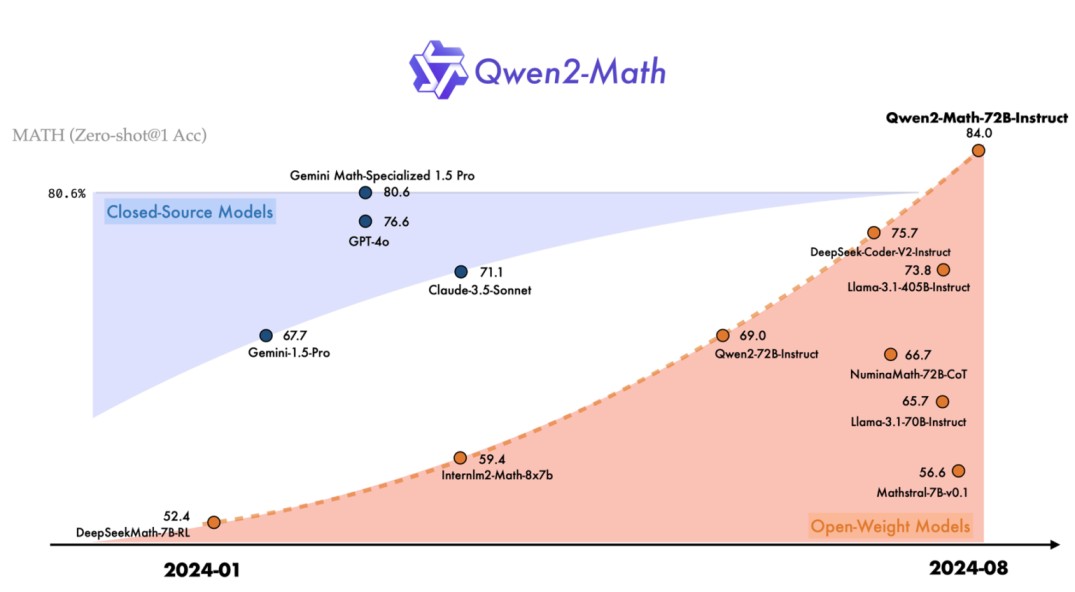
Qwen2-Math
- Advanced Mathematical Reasoning,
- Instruction-Tuned for Chat,
- Supports Fine-Tuning.
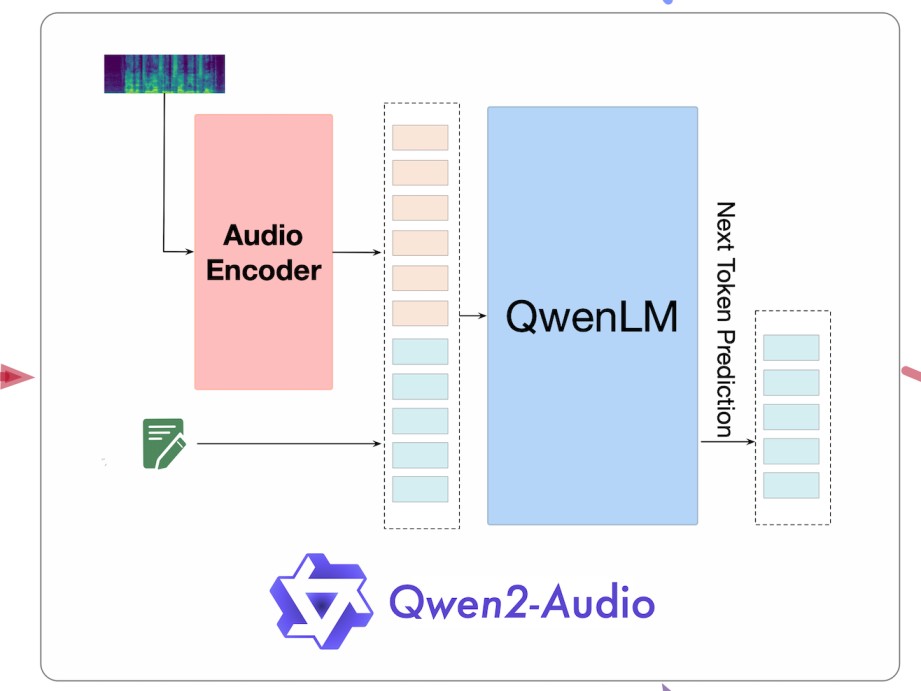
Qwen2-Audio
- High-Fidelity Audio Understanding
- Versatile Voice and Audio Analysis
- Seamless Multilingual Support
Qwen2-VL
- Advanced Visual Understanding
- Enhanced Video Comprehension
- Seamless Multimodal Integration
