To build an AGI system, a model must understand information across multiple modalities. With the rapid advancement of large language models, LLMs now excel in language comprehension and reasoning. Previously, Qwen Team extended their LLM, ‘Qwen’, to encompass additional modalities like vision and audio, resulting in the creation of Qwen-VL and Qwen-Audio. Today, they introduced Qwen2-Audio, the next iteration of Qwen-Audio, capable of processing both audio and text inputs to generate text outputs. Qwen2-Audio offers several key features:
- Voice Chat: For the first time, users can give instructions to the audio-language model via voice without needing ASR modules.
- Audio Analysis: The model can analyze various types of audio, including speech, sounds, and music, based on text instructions.
- Multilingual Support: The model supports over eight languages and dialects, including Chinese, English, Cantonese, French, Italian, Spanish, German, and Japanese.
Qwen Team releasing Qwen2-Audio-7B and Qwen2-Audio-7B-Instruct as open-weight models on Hugging Face and ModelScope, along with a demo for users to interact with.
Qwen2-Audio Performance
Developers conducted a series of experiments using benchmark datasets such as LibriSpeech, Common Voice 15, Fleurs, Aishell2, CoVoST2, Meld, Vocalsound, and AIR-Benchmark to evaluate the performance of Qwen2-Audio. These tests compared Qwen2-Audio with our earlier Qwen-Audio model as well as the state-of-the-art models in each task. The results, illustrated in the figure below, show that Qwen2-Audio consistently outperforms both previous SOTAs and our earlier Qwen-Audio model across all tasks.
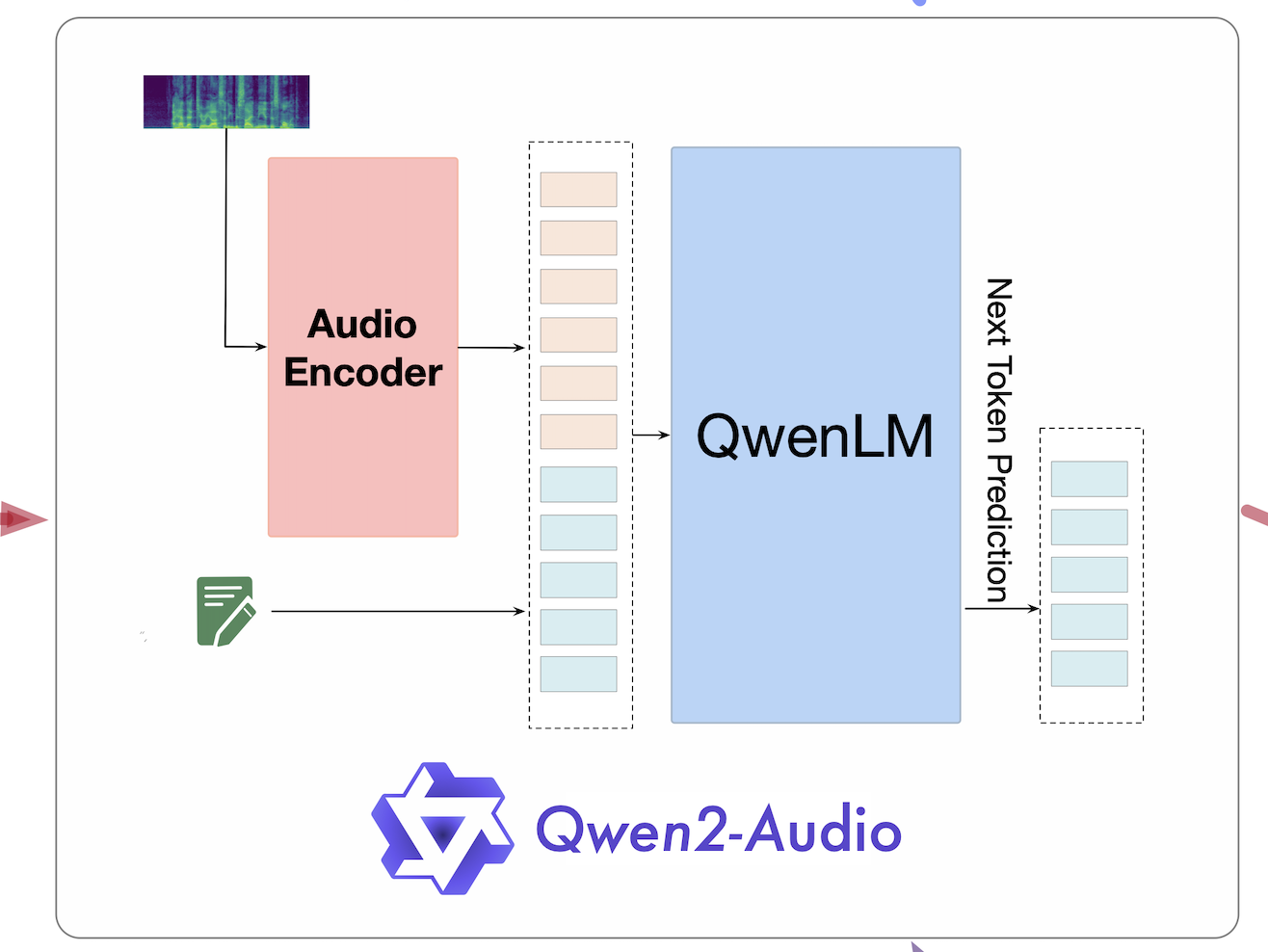
Architecture
The training architecture is illustrated below. We begin with the Qwen language model and an audio encoder as the foundational models. The process involves sequential multi-task pretraining to achieve audio-language alignment, followed by supervised fine-tuning and direct preference optimization. These steps are designed to enhance the model’s performance on downstream tasks and align it with human preferences.
Quickstart
Here’s a quick guide on how to use Qwen2-Audio-7B-Instruct for inference, supporting both voice chat and audio analysis modes. We utilize the ChatML format for dialog, and in this demo, you’ll learn how to effectively apply the apply_chat_template function to streamline the process.
Voice Chat Inference
In voice chat mode, users can interact with Qwen2-Audio purely through voice, without the need for any text input, allowing for a seamless and natural conversational experience.
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/guess_age_gender.wav"},
]},
{"role": "assistant", "content": "Yes, the speaker is female and in her twenties."},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/translate_to_chinese.wav"},
]},
]
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios = []
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]Audio Analysis Inference
In the audio analysis, users could provide both audio and text instructions for analysis:
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
{"type": "text", "text": "What's that sound?"},
]},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{"role": "user", "content": [
{"type": "text", "text": "What can you do when you hear that?"},
]},
{"role": "assistant", "content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property."},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
{"type": "text", "text": "What does the person say?"},
]},
]
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios = []
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(
librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]Batch Inference
Qwen2-Audio also supports batch inference as showed below:
from io import BytesIO
from urllib.request import urlopen
import librosa
from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
conversation1 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
{"type": "text", "text": "What's that sound?"},
]},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/f2641_0_throatclearing.wav"},
{"type": "text", "text": "What can you hear?"},
]}
]
conversation2 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
{"type": "text", "text": "What does the person say?"},
]},
]
conversations = [conversation1, conversation2]
text = [processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False) for conversation in conversations]
audios = []
for conversation in conversations:
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audios.append(
librosa.load(
BytesIO(urlopen(ele['audio_url']).read()),
sr=processor.feature_extractor.sampling_rate)[0]
)
inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
inputs['input_ids'] = inputs['input_ids'].to("cuda")
inputs.input_ids = inputs.input_ids.to("cuda")
generate_ids = model.generate(**inputs, max_length=256)
generate_ids = generate_ids[:, inputs.input_ids.size(1):]
response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)Qwen2-Audio Demo
Try Qwen2-Audio below and explore its cutting-edge capabilities.
Qwen2-Audio Technical Report
Explore Qwen2-Audio Technical Report below:
Next Step
This time we bring a new audio language model, Qwen2-Audio, which supports voice chat and audio analysis at the same time and understands more than 8 languages and dialects. In the near future, they plan to train improved Qwen2-Audio models on larger pretraining datasets, enabling the model to support longer audio (over 30s). Team also plan to build larger Qwen2-Audio models to explore the scaling laws of audio language models.