
Qwen2-VL is the latest addition to the vision-language models in the Qwen series, building upon the capabilities of Qwen-VL. Compared to its predecessor, Qwen2-VL offers:
- State-of-the-Art Image Understanding: Qwen2-VL excels in visual understanding across various resolutions and aspect ratios, achieving top performance on benchmarks like MathVista, DocVQA, RealWorldQA, and MTVQA.
- Extended Video Comprehension: Capable of analyzing videos over 20 minutes long, Qwen2-VL supports high-quality video-based question answering, dialog, and content creation.
- Advanced Agent Capabilities: With its complex reasoning and decision-making skills, Qwen2-VL can be integrated with devices such as mobile phones and robots to perform automated tasks based on visual and textual inputs.
- Multilingual Support: To cater to a global audience, Qwen2-VL understands text in images across multiple languages, including most European languages, Japanese, Korean, Arabic, and Vietnamese, in addition to English and Chinese.
Qwen Dev Team open-sourced Qwen2-VL-2B and Qwen2-VL-7B under the Apache 2.0 license, and the Qwen2-VL-72B API is now available! These models are integrated into Hugging Face Transformers, vLLM, and other third-party frameworks.
Qwen2-VL Model Capabilities
- Enhanced Recognition Capabilities
Qwen2-VL now features advanced object recognition, moving beyond basic plants and landmarks to understand complex relationships between multiple objects within a scene. The model’s ability to recognize handwritten text and multiple languages in images has also been significantly improved, making it more versatile and accessible to a global audience.
- Visual Reasoning: Solving Real-World Problems
In this update, Qwen2-VL’s mathematical and coding skills have been greatly enhanced. The model can analyze images to solve problems, interpret complex mathematical challenges through chart analysis, and accurately interpret highly distorted images. Enhanced capabilities in extracting information from real-world images and charts, coupled with improved instruction-following skills, enable the model to address practical issues, linking abstract concepts with actionable solutions.
- Video Understanding and Live Chat
Qwen2-VL extends its capabilities to video content, offering features such as video summarization, question answering, and real-time conversational support. This makes it a valuable personal assistant that provides insights and information directly from video content, enriching user interaction and support.
- Visual Agent Capabilities: Function Calling and Visual Interactions
As a visual agent, Qwen2-VL excels in Function Calling, allowing it to access real-time data through external tools by interpreting visual cues, such as flight statuses, weather updates, or package tracking. This integration of visual understanding with functional execution enhances its utility for information management and decision-making.
Additionally, Visual Interactions represent a significant leap towards emulating human perception. By engaging with visual stimuli as humans do, Qwen2-VL offers more intuitive and immersive interactions, acting not just as an observer but as an active participant in visual experiences.
Despite these advancements, the model has limitations, including an inability to extract audio from videos, knowledge updates only up to June 2023, and potential inaccuracies in handling complex instructions or scenarios. It also has some weaknesses in tasks involving counting, character recognition, and 3D spatial awareness.
Model Architecture
Qwen Dev Team built upon the Qwen-VL architecture, continuing to utilize a Vision Transformer (ViT) model in combination with Qwen2 language models. Across all variants, we employed a ViT with approximately 600 million parameters, designed to handle both image and video inputs seamlessly. To enhance the model’s ability to perceive and comprehend visual information in videos, we introduced several key upgrades:
One significant improvement in Qwen2-VL is the implementation of Naive Dynamic Resolution support. Unlike its predecessor, Qwen2-VL can handle arbitrary image resolutions, dynamically mapping them into a varying number of visual tokens. This ensures a consistent relationship between the model’s input and the inherent information within images, closely mimicking human visual perception. This upgrade allows the model to process images of any clarity or size effectively.
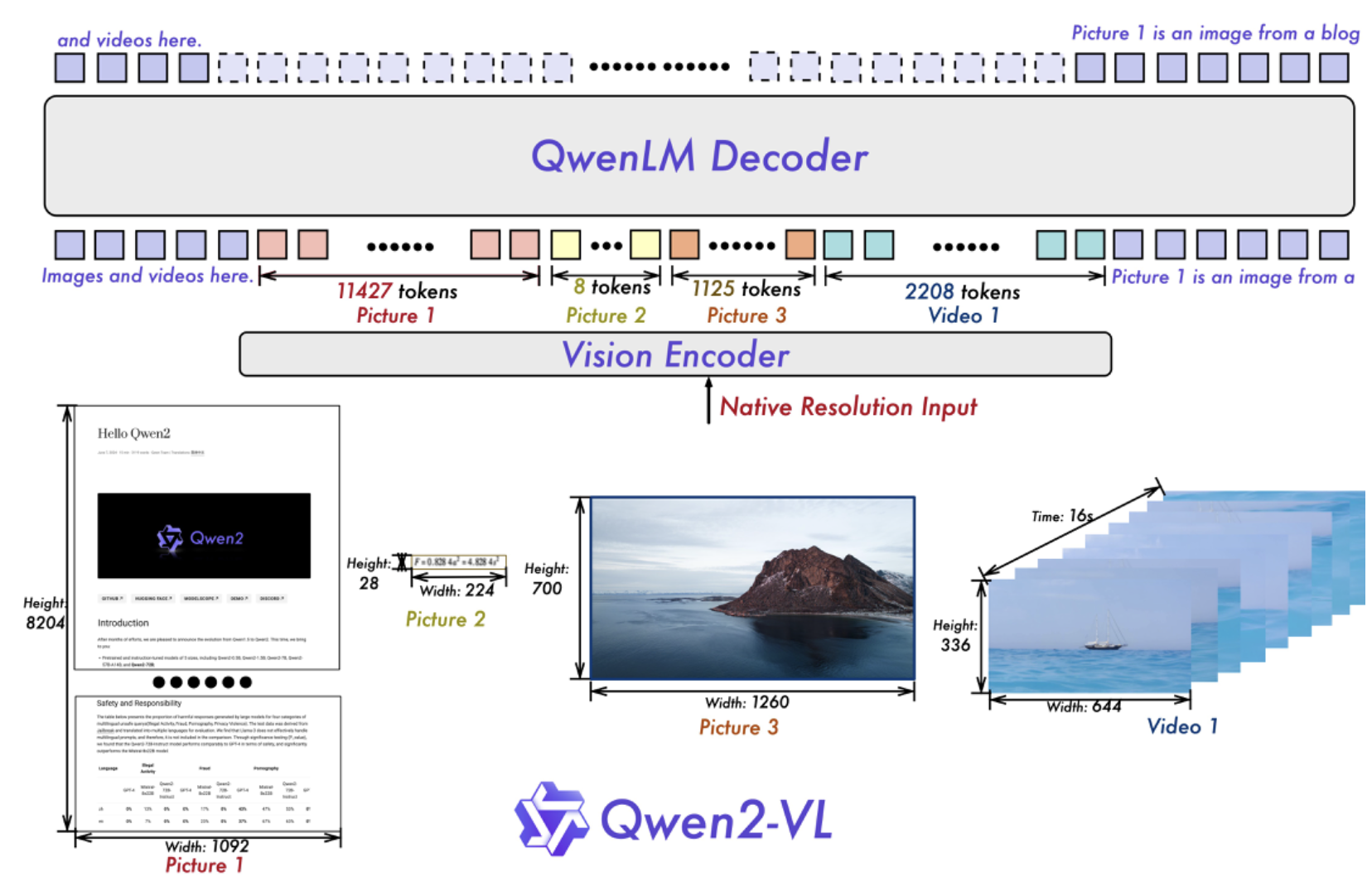
Another key architectural enhancement is the introduction of Multimodal Rotary Position Embedding (M-ROPE). This innovation deconstructs the original rotary embedding into three components, representing temporal and spatial (height and width) information. M-ROPE allows the model to simultaneously capture and integrate 1D textual, 2D visual, and 3D video positional information, enhancing the model’s ability to process and understand complex multimodal data.

Developing with Qwen2-VL
To utilize the largest Qwen2-VL model, Qwen2-VL-72B, you can access it temporarily through the official API. Simply sign up for an account, obtain your API key via DashScope, and follow the demonstration below to get started:
from openai import OpenAI
import os
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# Path to your image
image_path = "dog_and_girl.jpeg"
# Getting the base64 string
base64_image = encode_image(image_path)
def get_response():
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-vl-max-0809",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What is this?"},
{
"type": "image_url",
"image_url": {
"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"
},
},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
},
],
}
],
top_p=0.8,
stream=True,
stream_options={"include_usage": True},
)
for chunk in completion:
print(chunk.model_dump_json())
if __name__ == "__main__":
get_response()
The 2B and 7B models of the Qwen2-VL series are open-sourced and available on Hugging Face and ModelScope. You can explore their model cards for detailed usage instructions, features, and performance metrics. Below is a simple usage example with HF Transformers.
Ensure you install Transformers from the source using pip install git+https://github.com/huggingface/transformers, as the Qwen2-VL codes were just merged into the main branch. Without this, you may encounter a KeyError: 'qwen2_vl'.
To handle various visual inputs more conveniently, we offer a toolkit that supports base64, URLs, and interleaved images and videos. Install it with:
pip install qwen-vl-utilsHere’s a code snippet demonstrating its usage. We recommend using Flash Attention 2, if possible, for improved acceleration and memory efficiency.
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-7B-Instruct", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
Evaluation
Image Benchmarks
| Benchmark | InternVL2-8B | MiniCPM-V 2.6 | GPT-4o-mini | Qwen2-VL-7B |
|---|---|---|---|---|
| MMMUval | 51.8 | 49.8 | 60 | 54.1 |
| DocVQAtest | 91.6 | 90.8 | - | 94.5 |
| InfoVQAtest | 74.8 | - | - | 76.5 |
| ChartQAtest | 83.3 | - | - | 83.0 |
| TextVQAval | 77.4 | 80.1 | - | 84.3 |
| OCRBench | 794 | 852 | 785 | 845 |
| MTVQA | - | - | - | 26.3 |
| RealWorldQA | 64.4 | - | - | 70.1 |
| MMEsum | 2210.3 | 2348.4 | 2003.4 | 2326.8 |
| MMBench-ENtest | 81.7 | - | - | 83.0 |
| MMBench-CNtest | 81.2 | - | - | 80.5 |
| MMBench-V1.1test | 79.4 | 78.0 | 76.0 | 80.7 |
| MMT-Benchtest | - | - | - | 63.7 |
| MMStar | 61.5 | 57.5 | 54.8 | 60.7 |
| MMVetGPT-4-Turbo | 54.2 | 60.0 | 66.9 | 62.0 |
| HallBenchavg | 45.2 | 48.1 | 46.1 | 50.6 |
| MathVistatestmini | 58.3 | 60.6 | 52.4 | 58.2 |
| MathVision | - | - | - | 16.3 |
Video Benchmarks
| Benchmark | Internvl2-8B | LLaVA-OneVision-7B | MiniCPM-V 2.6 | Qwen2-VL-7B |
|---|---|---|---|---|
| MVBench | 66.4 | 56.7 | - | 67.0 |
| PerceptionTesttest | - | 57.1 | - | 62.3 |
| EgoSchematest | - | 60.1 | - | 66.7 |
| Video-MMEwo/w subs | 54.0/56.9 | 58.2/- | 60.9/63.6 | 63.3/69.0 |
Requirements
The code for Qwen2-VL is now included in the latest version of Hugging Face Transformers. We recommend building from source using the following command: pip install git+https://github.com/huggingface/transformers, as failing to do so might result in the error: KeyError: 'qwen2_vl'.
Quickstart
We provide a toolkit that simplifies handling various types of visual input, such as base64, URLs, and interleaved images and videos, as if you were using an API. You can install it with the following command:
pip install qwen-vl-utilsBelow is a code snippet demonstrating how to use the chat model with Transformers and qwen_vl_utils:
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
model_dir = snapshot_download("qwen/Qwen2-VL-7B-Instruct")
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# model_dir,
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained(model_dir)
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained(model_dir, min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)Image Resolution for Performance Boost
The model accommodates a broad spectrum of resolution inputs, utilizing native resolution by default. Higher resolutions can improve performance but require more computational resources. Users can adjust the minimum and maximum number of pixels to optimize their configuration, such as setting a token count range between 256 and 1280, to balance speed and memory usage effectively.
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained(
model_dir, min_pixels=min_pixels, max_pixels=max_pixels
)Qwen2-VL Demo
Try Qwen2-VL below and explore its cutting-edge capabilities:
Limitations
While Qwen2-VL excels in various visual tasks, it is crucial to acknowledge its limitations:
- Lack of Audio Support: The model does not process audio information within videos.
- Data Timeliness: The image dataset is current only up to June 2023, so information after this period may not be included.
- Constraints in Recognizing Individuals and Intellectual Property (IP): The model’s ability to identify specific individuals or IPs is limited and may not comprehensively cover all well-known personalities or brands.
- Limited Capacity for Complex Instructions: The model struggles with understanding and executing intricate multi-step instructions.
- Insufficient Counting Accuracy: Object counting, particularly in complex scenes, lacks high accuracy and needs improvement.
- Weak Spatial Reasoning Skills: The model struggles with accurately inferring object positions in 3D spaces, making it difficult to judge relative spatial relationships.
These limitations highlight areas for ongoing model optimization, and we are committed to continually enhancing Qwen2-VL’s performance and capabilities.
License
The open-source Qwen2-VL-2B and Qwen2-VL-7B models are released under the Apache 2.0 license.
What’s Next
Qwen eagerly anticipate your feedback and the creative applications you will develop with Qwen2-VL. Looking ahead, they plan to build even more robust vision-language models on next-generation language models, with the goal of integrating additional modalities to move closer to an omni-model!