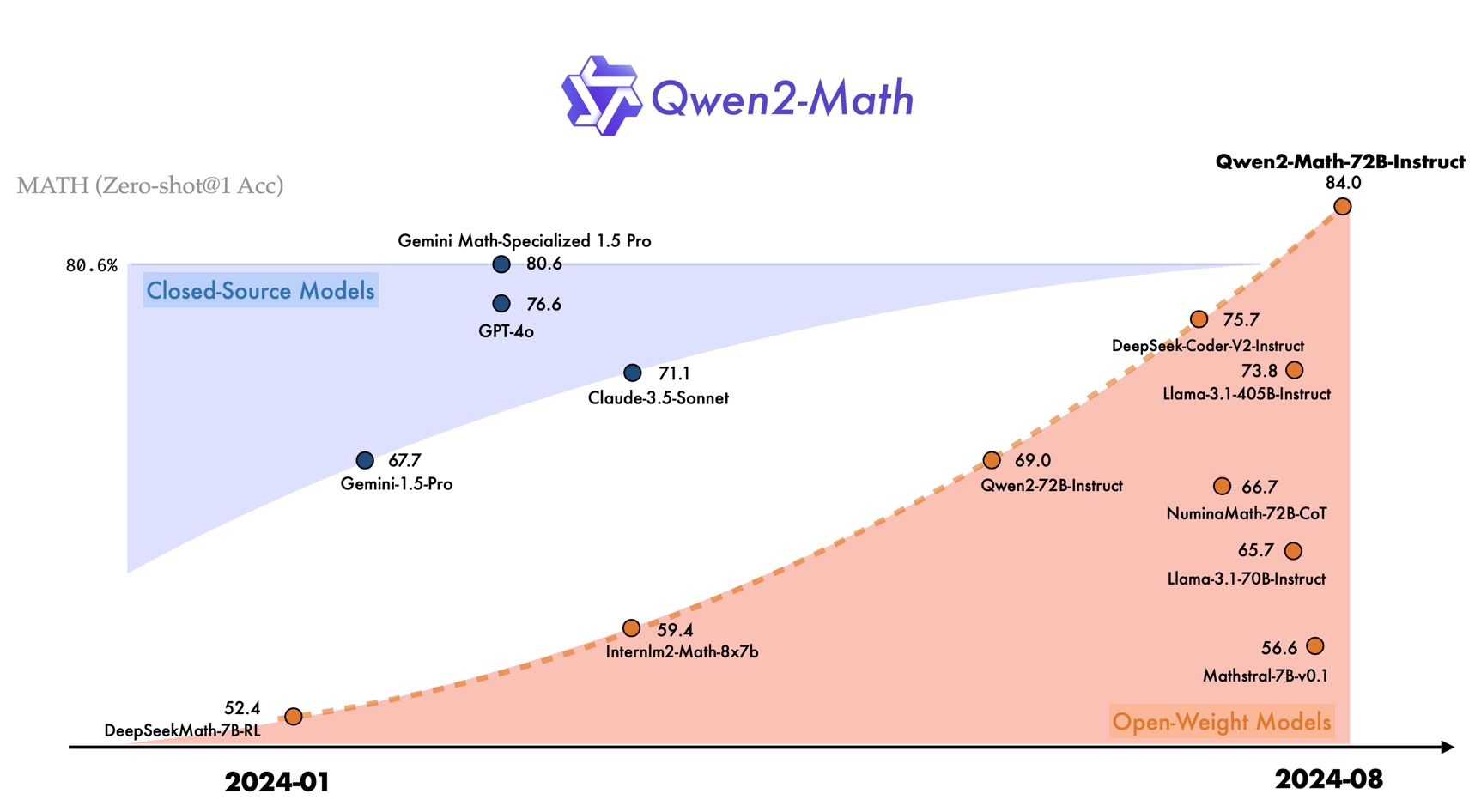
Qwen Dev Team are excited to unveil new series of math-focused models within the Qwen2 lineup: Qwen2-Math and Qwen2-Math-Instruct-1.5B/7B/72B. These specialized models, built on the Qwen2 LLMs, exhibit remarkable improvements in mathematical performance compared to both open-source and closed-source models, including GPT-4o. Qwen aim for Qwen2-Math to significantly advance the community’s ability to tackle complex mathematical challenges.
Qwen’s math-specific models have been evaluated using a range of mathematical benchmarks, and the results reveal that the largest model, Qwen2-Math-72B-Instruct, surpasses the performance of leading models such as GPT-4o, Claude-3.5-Sonnet, Gemini-1.5-Pro, Llama-3.1-405B.
Qwen2-Math base models
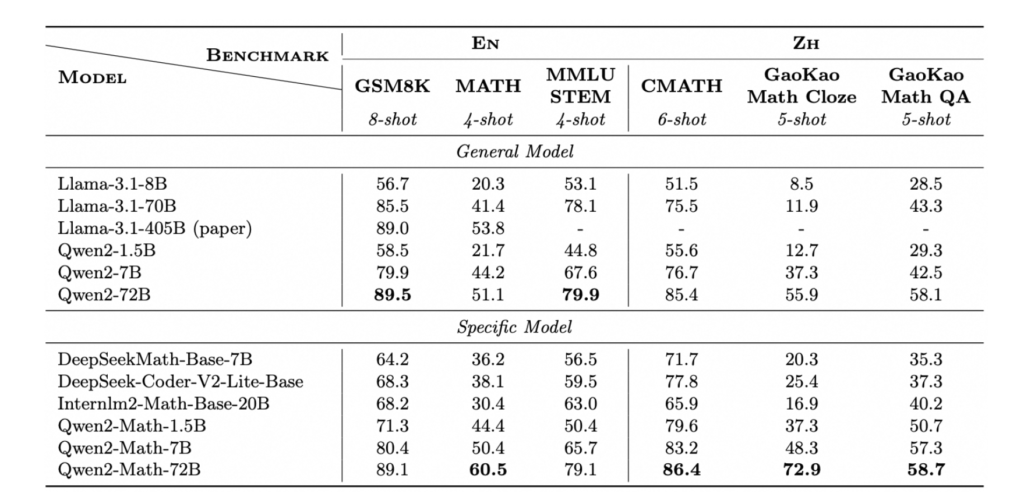
The Qwen2-Math base models start with the Qwen2-1.5B, 7B, or 72B configurations and are then pretrained using a specialized Mathematics-specific corpus. This corpus includes a comprehensive collection of high-quality mathematical texts from the web, books, codes, exam questions, and additional pre-training data curated by Qwen2.
We assess the Qwen2-Math base models using three prominent English math benchmarks: GSM8K, Math, and MMLU-STEM. Additionally, we evaluate them on three Chinese math benchmarks: CMATH, GaoKao Math Cloze, and GaoKao Math QA. All evaluations utilize few-shot chain-of-thought prompting.
Qwen2-Math-Instruct: Instruction-Tuned Models
To develop the Qwen2-Math-Instruct models, we began by training a math-specific reward model based on Qwen2-Math-72B. We integrated this dense reward signal with a binary indicator of correct answers to supervise the creation of SFT (Supervised Fine-Tuning) data via Rejection Sampling and to guide reinforcement learning using Group Relative Policy Optimization (GRPO) following SFT.
Qwen2-Math-Instruct has been rigorously evaluated on a variety of mathematical benchmarks in both English and Chinese. Alongside established benchmarks like GSM8K and Math, we included more challenging assessments such as OlympiadBench, CollegeMath, GaoKao, AIME2024, and AMC2023 for English, and CMATH, Gaokao (Chinese college entrance examination 2024), and CN Middle School 24 (China High School Entrance Examination 2024) for Chinese.
Performance metrics, including greedy, Maj@8, and RM@8, are reported for all benchmarks in a zero-shot setting, except for multiple-choice benchmarks (including MMLU STEM and multiple-choice problems in GaoKao and CN Middle School 24), where a 5-shot setting was used. Qwen2-Math-Instruct demonstrates superior performance among models of similar size, with RM@8 outperforming Maj@8, especially in the 1.5B and 7B models, highlighting the effectiveness of Qwen’s math reward model.
Requirements
transformers>=4.40.0for Qwen2-Math models. The latest version is recommended.
Quick Start
Qwen2-Math-72B-Instruct is designed for interactive chatting, while Qwen2-Math-72B serves as a base model ideal for completion tasks and few-shot inference, making it an excellent starting point for fine-tuning.
Hugging Face Transformers
Qwen2-Math can be deployed and inferred similarly to Qwen2. Below is a code snippet demonstrating how to use the chat model with Transformers:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "qwen/Qwen2-Math-72B-Instruct"
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Find the value of $x$ that satisfies the equation $4x+5 = 6x+7$."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]Qwen2-Math-Instruct Demo
You can try Qwen2-Math-Instruct below:
Summary
Dev Team excited to introduce new model series, Qwen2-Math, which builds upon the Qwen2 foundation with a focus on mathematical capabilities.
The flagship model, Qwen2-Math-72B-Instruct, exceeds the performance of proprietary models like GPT-4o and Claude 3.5 in math-related tasks. Currently available in English only, Developers from Qwen plan to release bilingual models supporting both English and Chinese soon, with multilingual models also in development. Team commitment to advancing the ability of their models to tackle complex and challenging mathematical problems will continue.