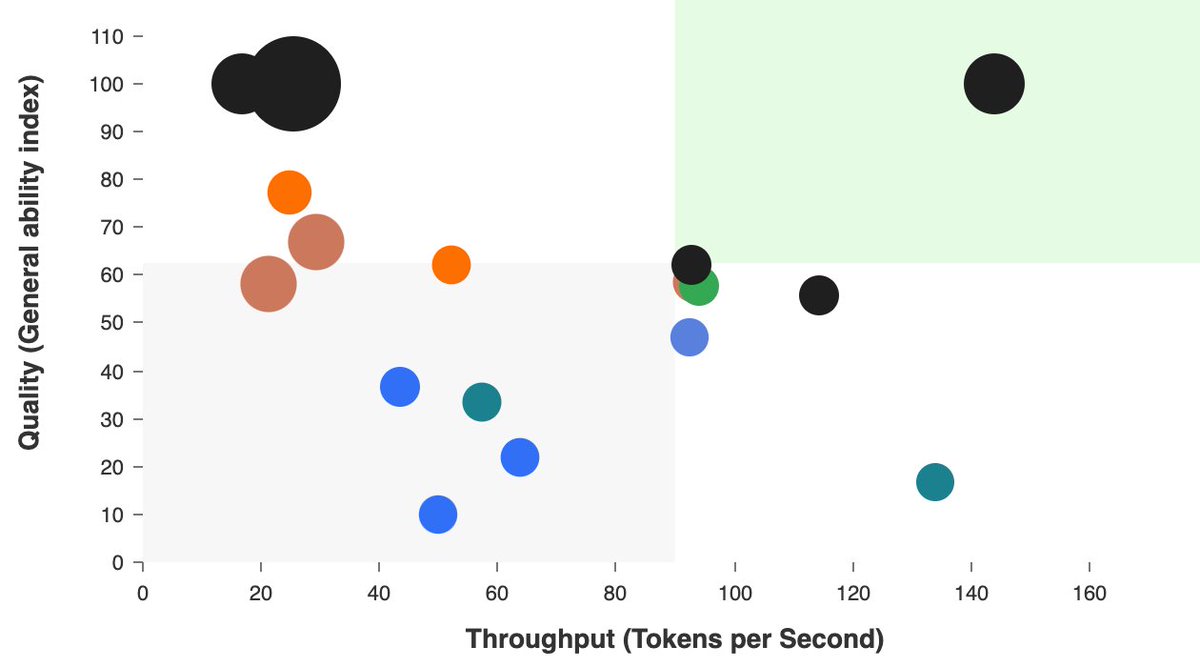
Benchmarks of providers of Qwen2.5, a leading open-source model family. Qwen2.5 family of models includes Qwen2.5 72B, Qwen2.5 Coder 32B and a range of smaller models including 1.5B and 0.5B models for ‘edge’ use-cases. Qwen2.5 72B, the flagship model, is competitive in intelligence evaluations with frontier models including Llama 3.3 70B, GPT-4o and Mistral Large 2.
Despite its smaller size, Qwen 2.5 Coder 32B achieves comparable performance in coding benchmarks like HumanEval to frontier models. Its size and capabilities position it well to support developers with fast code generation and emerging use-cases such as coding agents that require multi-step inference to autonomously develop features and applications.
Amongst providers, @SambaNovaAI is the clear leader in output speed, delivering ~225 output tokens/s on Qwen2.5 72B, and 566 output tokens/s on Qwen 2.5 Coder 32B in our coding workload benchmark. @nebiusai , @DeepInfra , @hyperbolic_labs and @togethercompute are also offering the model(s) and all at prices significantly cheaper than comparable proprietary models such as GPT-4o. Links to our live benchmarks of Qwen2.5 on Artificial Analysis below.
Qwen2.5 Coder 32B Output speed benchmarks
Artificial Analysis‘s coding workload benchmark includes using coding focused prompts covering a variety of different programming languages. It is not yet present on the Artificial Analysis website but soon will be for coding-focused models.
Qwen2.5 comparison to other models:
https://artificialanalysis.ai/models/qwen2-5-coder-32b-instruct/providers

We’ve learned that you can use SambaNova’s (and others’) endpoint with
@continuedev for ultra-fast code generation within VSCode using Qwen2.5 Coder 32B.
@SambaNovaAI has shared that they are using speculative decoding on their endpoint. This speeds up output speed significantly as code is relatively low entropy (e.g. after ‘if __name__ ==’ there is a high likelihood “__main__” follows) which results in a relatively high match rate of the draft model to the primary model.